本來默默劃船��,在交流會上談個性化推薦都不惹人注意的今日頭條,毫無置疑現(xiàn)在已經(jīng)被整個BAT圍剿���,內(nèi)容領域的企業(yè)不自覺把今日頭條當做競爭對手��,非內(nèi)容領域的互聯(lián)網(wǎng)公司也都想來分一杯內(nèi)容的羹�����,一夜間�,互聯(lián)網(wǎng)遍地都是feed流��,不談內(nèi)容推薦算法都不好意思上桌了�����。
筆者有幸從0到1規(guī)劃頭條產(chǎn)品����,想把自己的實操經(jīng)驗分享出來,如果對感興趣的朋友有幫助自然開心��,更希望得到業(yè)界大佬的批評和指正���,畢竟一個人摸索前進�,還是很危險的。
1.明確定位
經(jīng)常使用閱讀產(chǎn)品很大的感受是大平臺很容易出現(xiàn)資訊沒深度����,垂直的內(nèi)容資訊只在某幾個如科技,互聯(lián)網(wǎng)等幾個領域做的還不錯�����,我當時的設想是有沒有可能做行業(yè)內(nèi)深度資訊����,尤其是一開始切入那些并未互聯(lián)網(wǎng)化過深的行業(yè),通過一個行業(yè)的試點����,形成行業(yè)頭條,在沉淀優(yōu)質(zhì)行業(yè)知識的同時�,以最低成本去復制到其他行業(yè)。
思考了挺久之后開始和老板匯報了����,省去10000字具體說服過程�����,最終同意了,因為團隊某公司與一個傳統(tǒng)行業(yè)A有交集���,所以一開始的切入行業(yè)就是行業(yè)A了�����,下面開始具體執(zhí)行了�,看著一共10多個技術人員�����,我陷入了深思……
劣勢簡直不要太明顯:
我要開始作死地做頭條產(chǎn)品了……
2. 頭條產(chǎn)品整體設計
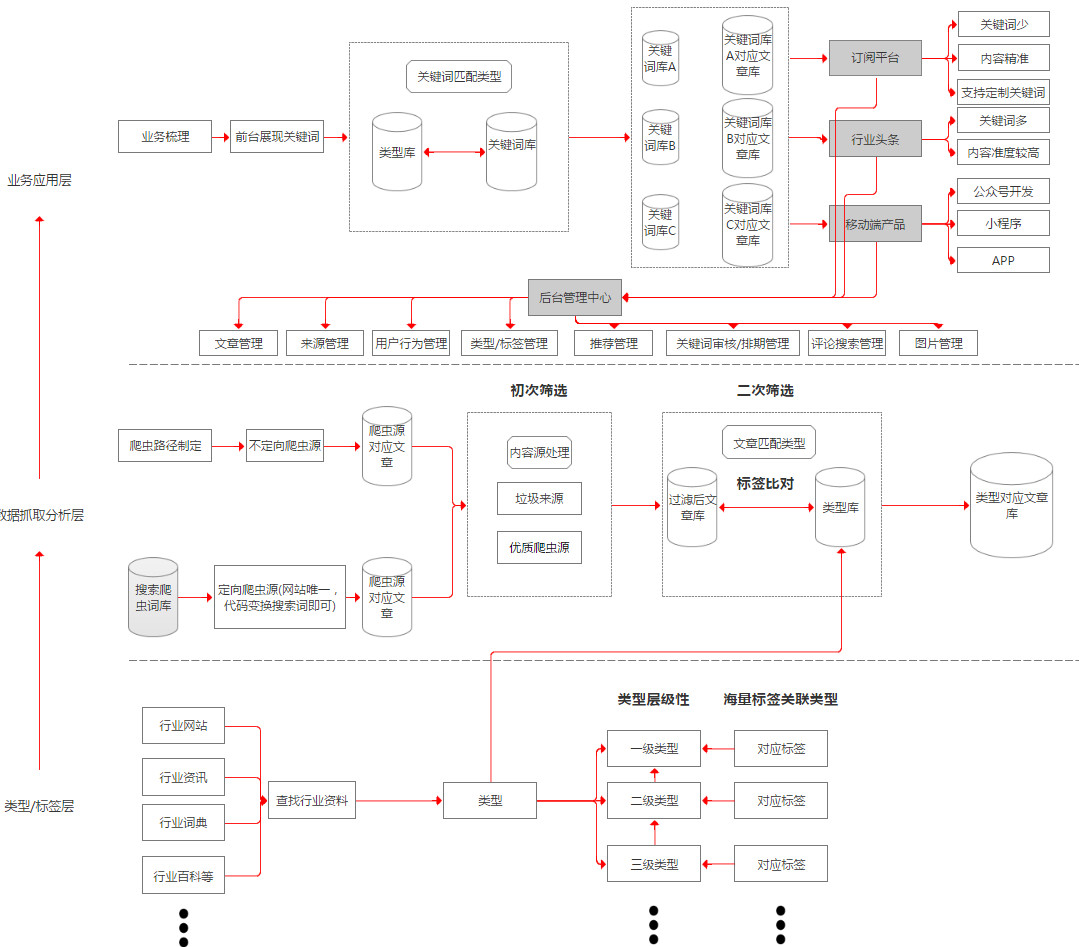
我開始從三個層面去搭建產(chǎn)品,底層類型標簽層��,中層數(shù)據(jù)抓取分析層��,頂層業(yè)務應用層���。
底層類型標簽層
底層根據(jù)具體行業(yè)進行梳理��,本來這個過程應該產(chǎn)品和具體行業(yè)從業(yè)人員配合梳理����,但是礙于資源有限����,那就我來吧,肯定不足夠詳盡�����,但是一開始可以先跑起來��。
底層類型標簽層分為類型和標簽�,類型有層級性,數(shù)據(jù)庫預留到7級�,實際梳理到3級就差不多了���,如行業(yè)A�,A公司是一個一級類型,A行業(yè)制造公司是二級分類�����,具體制造公司名稱是3級類型����,每個類型獨立建表,每個表里關聯(lián)海量標簽到類型上�����,如行業(yè)A技術這個類型里我們找到行業(yè)A技術術語詞典�����,刪選后就作為標簽關聯(lián)到A技術這個類型下面����,類型數(shù)最后梳理了600多,標簽數(shù)量有10萬多���,數(shù)據(jù)庫預留狀態(tài)位��,可以視情況進行啟用關閉�����。
中層數(shù)據(jù)抓取分析層
數(shù)據(jù)抓取分析層分為爬蟲部署����,內(nèi)容來源處理,數(shù)據(jù)歸類���。
1��、爬蟲部署
我以一個技術外行的角度把爬蟲分為兩類����,一類是不定向爬蟲�����,都是一個個單獨網(wǎng)站�����,這種技術消耗較大,需挨個處理���,如各個A行業(yè)公司的官網(wǎng)新聞中心和行業(yè)A平臺網(wǎng)站�,需單獨處理���,另一類定向爬蟲,主要是有搜索功能的大資訊平臺����,如今日頭條等,代碼可復用���,寫好之后我直接建了一張表����,專門放搜索爬蟲的關鍵詞�,一堆關鍵詞一套代碼就可以實現(xiàn),輸入進去就把含有這些關鍵詞的新聞抓取出來了�,現(xiàn)在這張表關鍵詞也有700多了,爬取來的內(nèi)容量實在太大���,建議用mongedb處理��。
2��、內(nèi)容來源處理
數(shù)據(jù)過來后先進行來源梳理���,劃分優(yōu)質(zhì)來源和垃圾來源����,提升優(yōu)質(zhì)來源內(nèi)容的權重�,優(yōu)質(zhì)來源主要是各公司官網(wǎng),垃圾來源是指對具體行業(yè)而言�,大量無意義的內(nèi)容來自同一個來源,那么將他認定為垃圾來源���,比如一個叫xx說車的來源在建筑行業(yè)被認定為垃圾來源���,但是將來復制到汽車這個領域的時候,就不再是垃圾來源了�����,垃圾來源是一個長期的活���,現(xiàn)在大概700多了����,大部分垃圾來源是今日頭條的頭條號。
3�、數(shù)據(jù)歸類
過濾完垃圾源之后,就開始數(shù)據(jù)歸類了����,本質(zhì)上是將新聞內(nèi)容歸到我們建立的一個個類型上,因為做行業(yè)資訊�����,希望一開始數(shù)據(jù)準度較高�,我當時想了兩種方案�����,第一種是將類型根據(jù)自己關聯(lián)的海量標簽按權重建立一個個模型����,所有抓取來的文章做全文的分詞處理,大量文章統(tǒng)計詞頻�,每篇文章所有分詞就有一個總的頻率值,和類型模型比對,取相關性較高的�����,另一種就是把類型下面所屬的標簽和所有篩選過垃圾源的文章比對��,含有標簽的文章歸到所屬類型下面���,含有同一類型標簽越多�,說明該文章相關性越高���,為了快速上線就用第二種方案��,但是相對�����,精度就差了一些�����,當然隨著人工的介入�,篩出一系列垃圾源��,類型和標簽維護工作的持續(xù),內(nèi)容準度好了一些���。
頂層業(yè)務應用層
業(yè)務展現(xiàn)層主要是梳理目標用戶感興趣的關鍵詞��,將這些關鍵詞關聯(lián)到類型標簽層的類型�����,這樣�����,用戶訂閱關鍵詞之后就可以看到這個關鍵詞所屬的內(nèi)容�����,前臺現(xiàn)在以及上線2個產(chǎn)品,一個訂閱平臺�����,行業(yè)頭條��,與之配套的是后臺管理中心�。
1、訂閱平臺
訂閱平臺半封閉,面向行業(yè)A企業(yè)用戶和行業(yè)A自媒體從業(yè)者����,釋放出他們感興趣的關鍵詞,內(nèi)容準度更高�����,企業(yè)用戶訂閱關鍵詞����,可以看到相關的資訊,看到平臺具有的能力后��,有欲望定制更多關鍵詞�����,后臺審核后繼續(xù)部署爬蟲�����,推送數(shù)據(jù)給用戶����,同時記錄用戶的所有行為數(shù)據(jù)�。
2���、行業(yè)頭條
行業(yè)頭條完全開放�,面向準行業(yè)從業(yè)者以及泛行業(yè)愛好者�����,釋放出更多關鍵詞�����,但是較訂閱平臺���,內(nèi)容質(zhì)量稍差�,但是目標用戶較廣��,所以寄希望記錄用戶的所有行為數(shù)據(jù)(如評論�����,閱讀量����,換一批事件,關注關鍵詞等)��,得到用戶反饋�,建立用戶畫像,以達到根據(jù)不同用戶畫像推薦關鍵詞的效果�����,為真正的推薦做準備�。
3、后臺管理中心
含有新聞管理���,來源管理(優(yōu)質(zhì)來源����,垃圾來源)�,類型/標簽管理,用戶行為管理�,推送管理,關鍵詞審核排期管理�,評論搜索管理等,具體就不再詳述了����,有機會再詳細介紹�,簡單的把產(chǎn)品框架梳理了一張圖��,和上面的論述結合起來��,可能更方便理解�����。
3. 致同行
不要動不動就要再造個今日頭條��,如果你的體驗和算法做不到比他強百分之五十以上�,正面硬剛基本沒戲,找準自己的切入點�����,認清自己的優(yōu)勢��;
內(nèi)容推薦從來都很危險�����,如果用戶不需要的時候推薦�,除非做到讓用戶驚喜����,否則就是減分�����,用戶一定要用的產(chǎn)品�,用戶只能忍著�,可有可無的產(chǎn)品,極有可能被用戶卸載�����,這點做公眾號的朋友肯定深有感觸���,每次推送內(nèi)容都怕掉粉�。
因為對搜索一直比較有興趣�����,所以簡單闡述一下自己對輸入法產(chǎn)品想做內(nèi)容的建議吧�。
用戶有自己了解資訊的需求:
- 主動獲取:RSS抓?。╣oogle訂閱),關注/訂閱(即刻)
- 被動獲?����。浩脚_推薦(傳統(tǒng)門戶,新聞網(wǎng)站)�,垂直類媒體資訊(36K,虎嗅等����,最近馮大輝的readhub),個性化推薦(頭條���,一點資訊)
這一類需求競爭極其大����,還有一類是基于特定場景下���,對資訊的了解訴求����。
比如找工作時����,想了解某家公司;吃飯時,想了解附近餐館的情況���。
這一類訴求特別長尾�,目前多是怎么被滿足的呢�?
主動搜索����,到百度,知乎等平臺搜索����,但得到想要的資訊路徑很長,比如你和朋友吃飯��,你想知道附近有哪些好館子�,搜到的代價就就極高這種場景大量發(fā)生在哪里?聊天和查詢的時候�����!這正是我覺得輸入法切入資訊的機會�����,具體來講:
- 當和別人聊天說要跳槽,談的某家公司���,輸入法輸入時有個提示(如顏色變化等)能方便的推送公司的最新資訊�����;
- 聊天約飯�����,方便推送出附近飯館和評價����;
- 和男朋友說要買趙麗穎同款��,男朋友能方便看到這些商品的資訊�;
這些訴求的背后數(shù)據(jù),詞匯出現(xiàn)的頻率����,輸入法公司應該有足夠的積累,大可根據(jù)詞頻做內(nèi)容準備����,當用戶在輸入東西的時候�,給用戶一個意外的驚喜��,來達到資訊推薦的目的��,希望有從事輸入法這塊的朋友能給予指導吧�����。